
编码器详解
|
编码器名称 |
优点 |
缺点 |
|
|
– |
不支持扩散模型 |
|
|
最还原音色、有大型底模、支持响度嵌入 |
咬字能力较弱 |
|
|
咬字能力较强 |
音色泄露 |
|
|
咬字最强 |
音色泄露、显存占用高 |
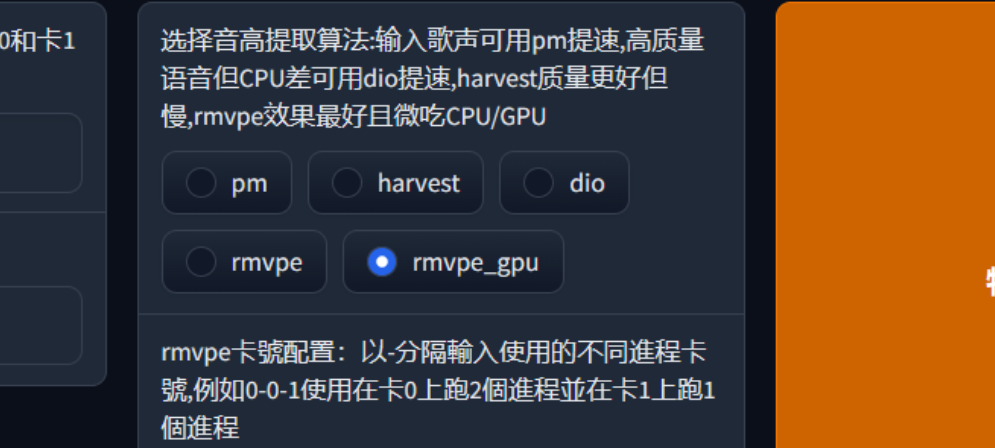
更多的编码器选项,请参考 训练参数详解 – 关于特征编码器
🦻音色泄露指的是输出的音色向底模/推理输入源的原始音色接近,模型说话人越多,音色泄露越严重。考虑到大多数人都希望尽可能还原目标说话人的音色,因此音色泄露被认为是一种不受欢迎的结果。
- 如要训练扩散模型或启用响度嵌入,请自行勾选
勾选训练扩散后将会提取扩散模型所需的特征文件,会占用更多硬盘空间。有关扩散模型的详细说明,请参考训练参数详解。
⚠️启用响度嵌入需要选择 Vec768L12 编码器,其它编码器没有响度嵌入的底模。
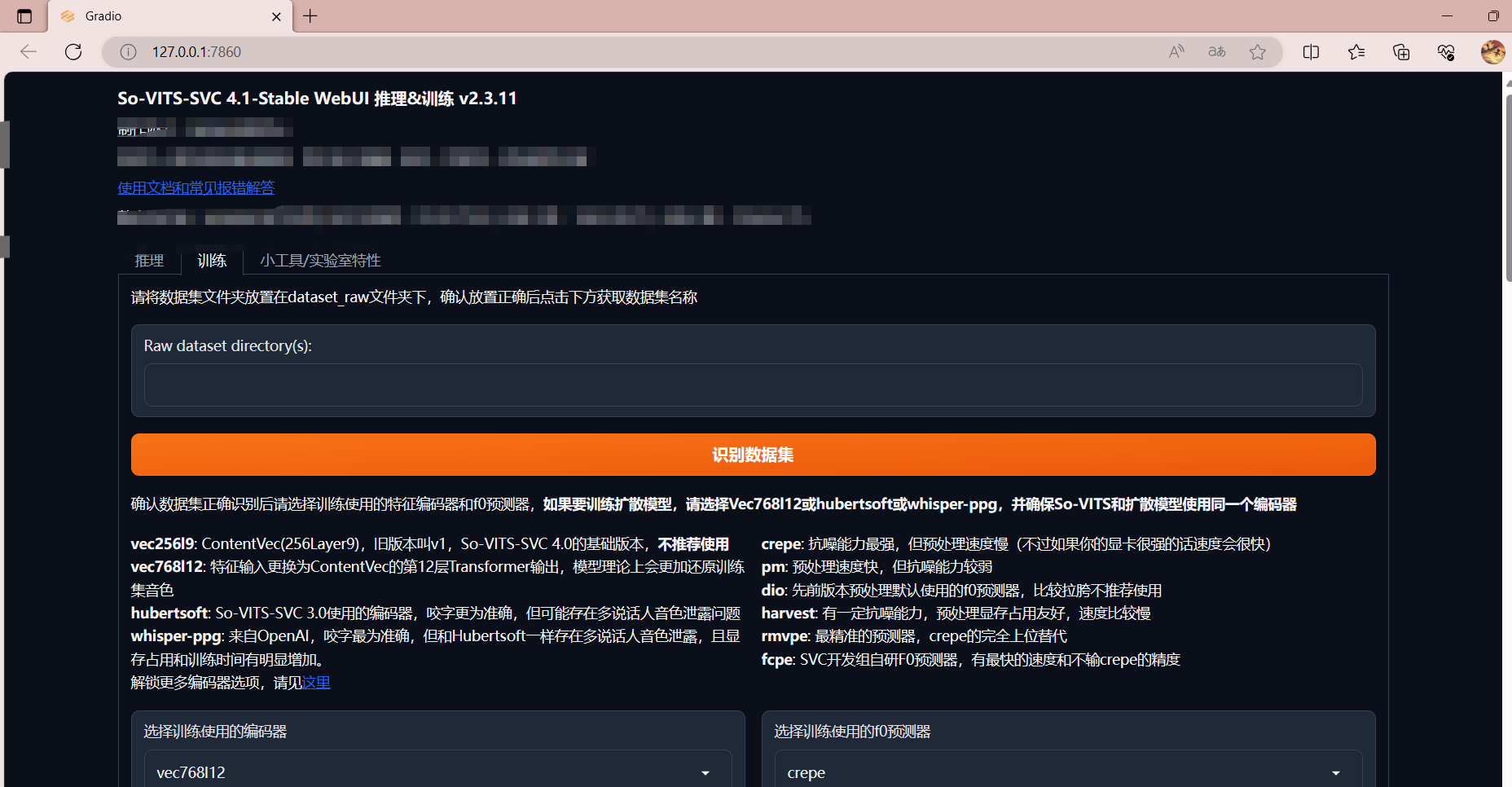
- 点击数据预处理
数据预处理的输出信息中可能存在报错信息。如果出现报错,则代表数据预处理未完成。你可以参考常见报错和解决方案自行排障。
⚠️数据预处理可以多进程执行,但会显著占用显存和内存。建议 6G 以下显存不要开启多线程。12G 以下显存不要将线程数设置为 2 以上。
⚠️同一个数据集只需要预处理一次,往后继续训练不需要也不可以重新预处理!
最佳实践
如果你是初次接触,面对眼花缭乱的可选项,不知道该如何设置预处理参数,这里为你提供了一些不同使用场景下的最佳实践:
用于翻唱(非实时转换):
|
编码器 |
f0 预测器 |
响度嵌入 |
跳过响度匹配 |
TINY |
浅扩散 |
|
vec768l12 |
rmvpe |
√ |
√ |
× |
√ |
用于朗读 / 说话(非实时转换):
© 版权声明
模型版权归作者所有,仅供娱乐,请于下载后24小时内删除。侵权联系 mxgf.cc@foxmail.com
THE END




























暂无评论内容