
Sovits的原理是通过将输入音频进行特征提取和模型转换,将其转换为具有特定特征的语音。具体来说,Sovits首先使用SoftVC内容编码器提取源音频的语音特征,然后将这些特征与F0(音高)同时输入到VITS中进行替换,从而将文本转换为具有特定特征的语音。
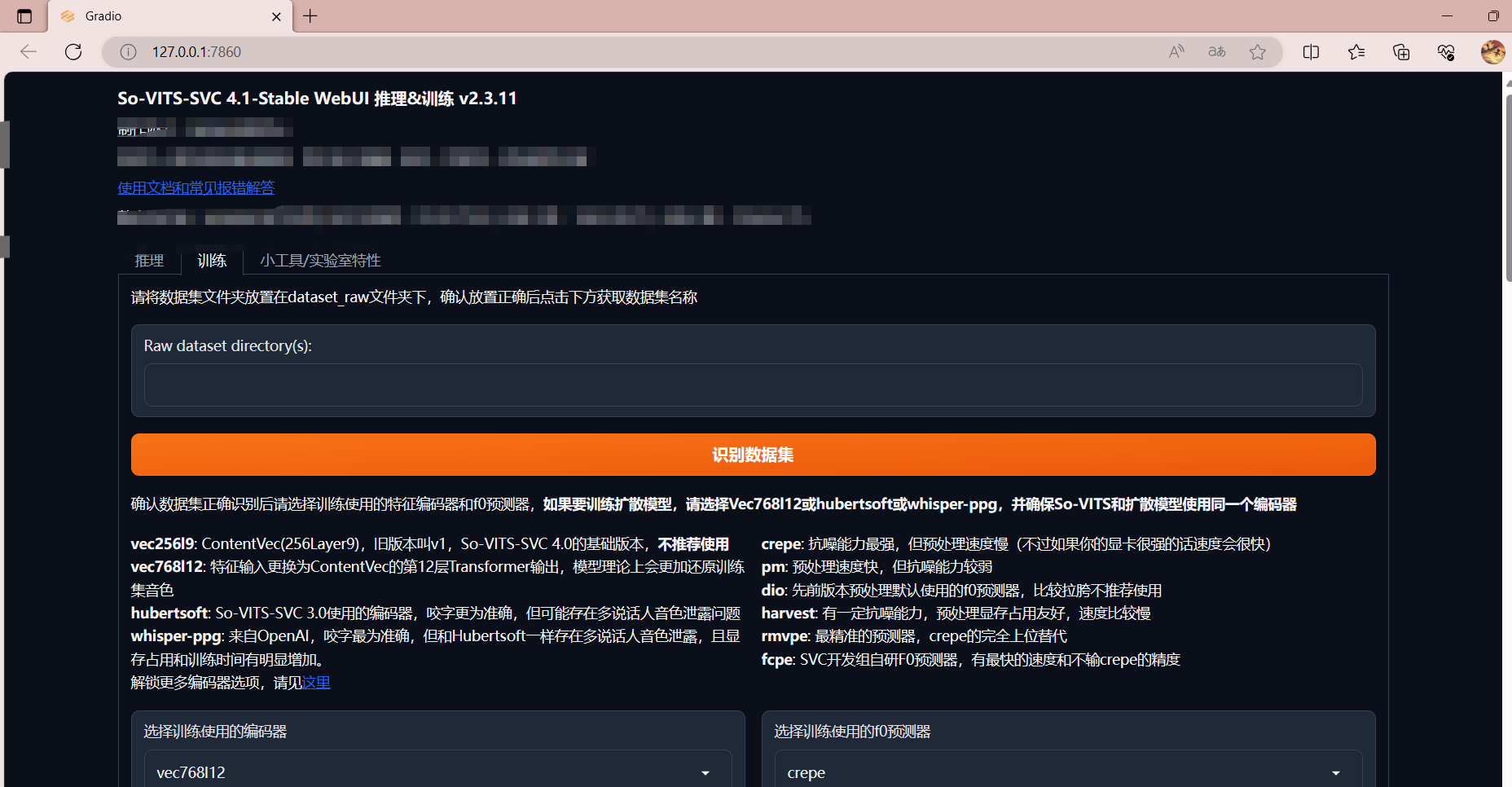
要训练一套自己的模型,可以按照以下步骤进行:
- 收集语音数据:首先需要收集大量的语音数据,包括您希望转换的声音和目标声音的数据。
- 数据预处理:对收集到的数据进行预处理,包括声音的标准化、归一化等操作,以便于后续的特征提取和模型训练。
- 特征提取:使用类似于SoftVC的内容编码器提取语音数据的特征,这些特征将用于后续的模型转换。
- 模型训练:将提取的特征和目标声音的数据输入到Sovits模型中进行训练。这个过程可能需要较长时间,具体取决于数据量和计算机性能。
- 模型评估和调整:在训练完成后,可以使用一些评估指标对模型的性能进行评估,并根据评估结果进行调整和优化。
- 使用模型进行转换:一旦训练和评估完成,就可以使用该模型将其他声音转换为具有特定特征的语音了。
© 版权声明
模型版权归作者所有,仅供娱乐,请于下载后24小时内删除。侵权联系 mxgf.cc@foxmail.com
THE END




























暂无评论内容