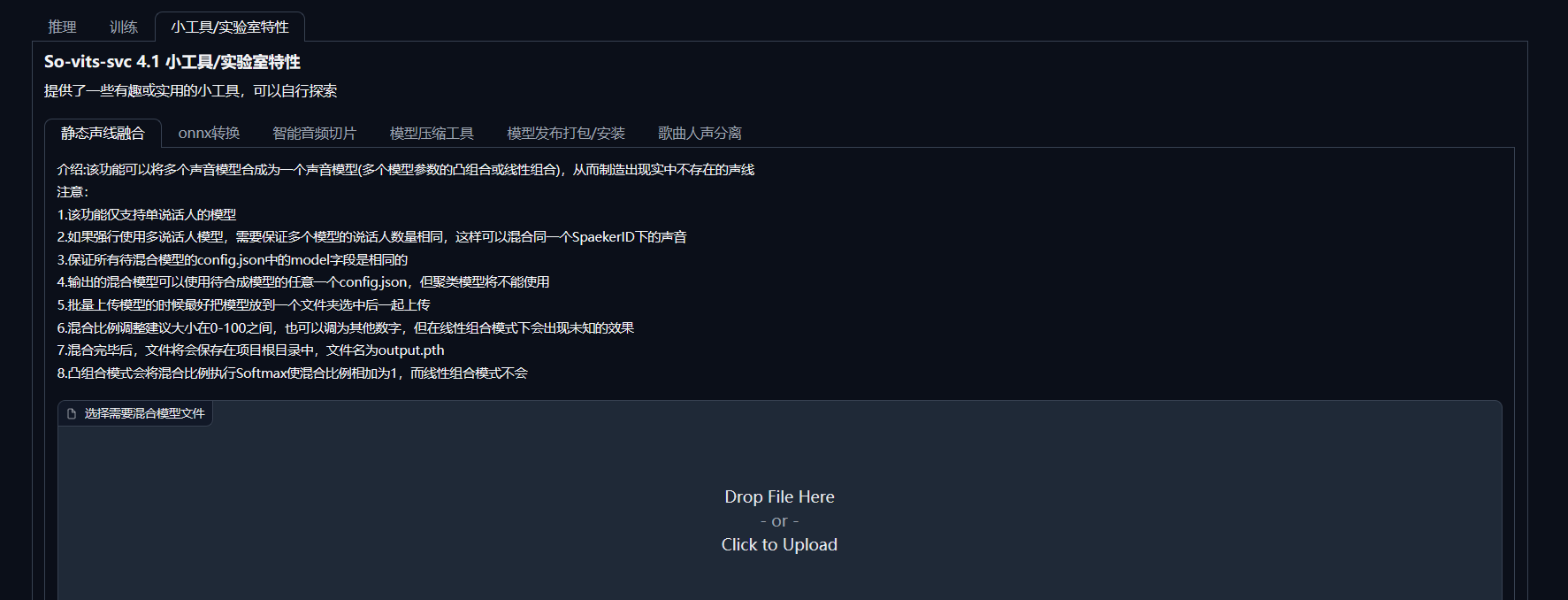

介绍
该功能可以将多个声音模型合成为一个声音模型(多个模型参数的凸组合或线性组合),从而制造出现实中不存在的声线。
静态声音融合的优点:
- 创造多样性:通过将多个不同的声音模型融合,可以生成具有多样性的声线。这些声线可能比单一模型生成的声线更具吸引力、更富有变化,从而为声音设计提供更多的选择。
- 弥补单一模型的局限性:每个声音模型都有其自身的优点和局限性。通过将多个模型融合,我们可以利用它们的优点并弥补它们的不足,从而生成更自然、更真实的声线。
- 扩大声音库:通过融合多个声音模型,我们可以创建更大规模的声音库。这些声音库可以用于多种应用,如电影音效设计、游戏音效设计、虚拟现实音效设计等。
- 控制声音特征:声音模型融合可以让我们更好地控制声音的各个特征,如音调、音色、音量等。通过调整不同模型的权重和参数,我们可以得到具有特定特征的声音,从而实现个性化的声音设计。
融合步骤
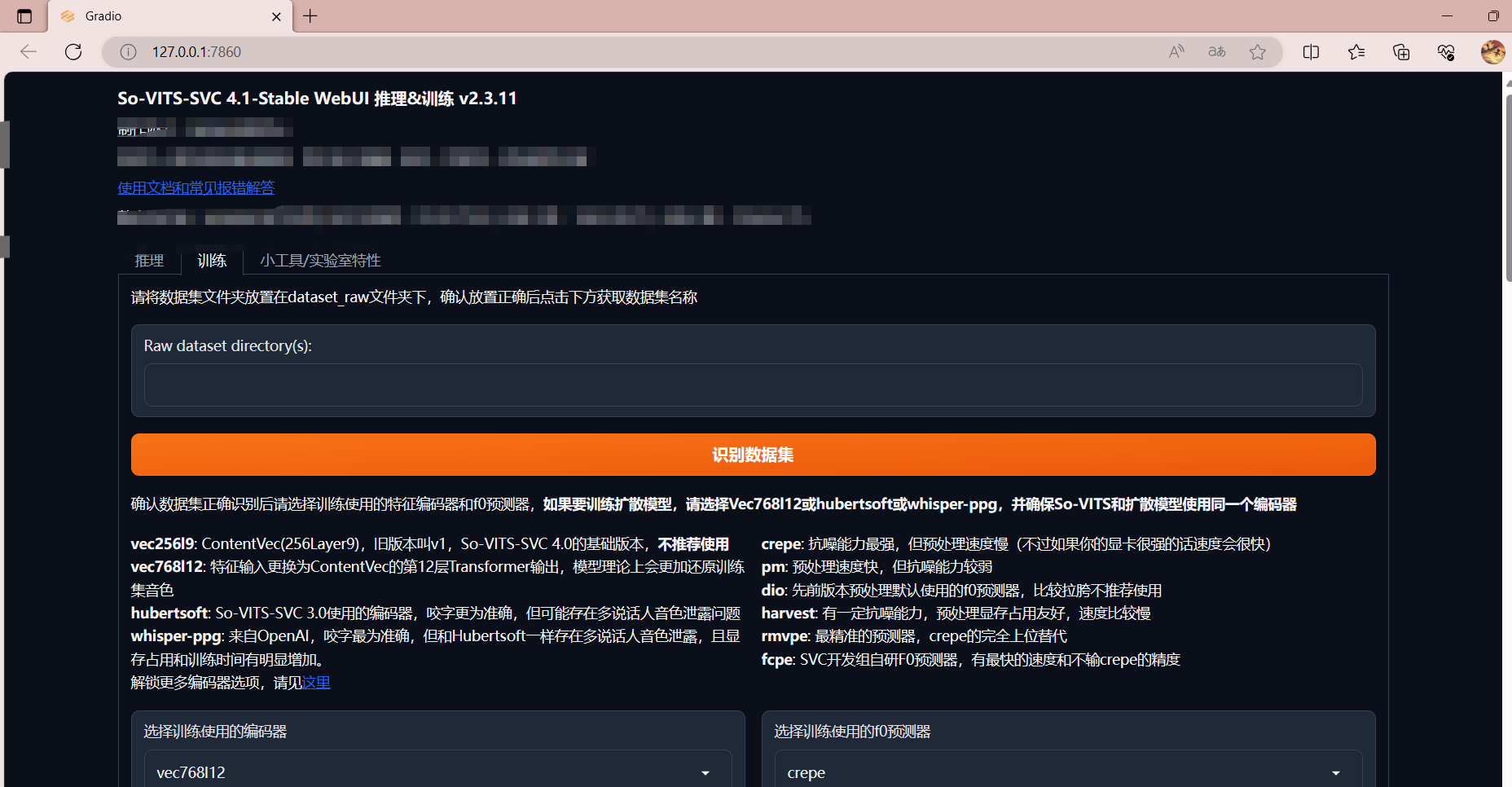
1,启动 So-VITS-SVC 新版
该功能仅在4.1版本以上才有
2,小工具/实验室特性
注意:
1.该功能仅支持单说话人的模型
2.如果强行使用多说话人模型,需要保证多个模型的说话人数量相同,这样可以混合同一个SpaekerID下的声音
3.保证所有待混合模型的config.json中的model字段是相同的
4.输出的混合模型可以使用待合成模型的任意一个config.json,但聚类模型将不能使用
5.批量上传模型的时候最好把模型放到一个文件夹选中后一起上传
6.混合比例调整建议大小在0-100之间,也可以调为其他数字,但在线性组合模式下会出现未知的效果
7.混合完毕后,文件将会保存在项目根目录中,文件名为output.pth
8.凸组合模式会将混合比例执行Softmax使混合比例相加为1,而线性组合模式不会
选中两个模型
3,声线融合启动
4,注意事项
模型必须是无压缩,且相同平台的模型,才可以进行融合
模型输出的路径在 So-VITS-SVC 根目录下的output.pth 模型文件
config文件 可以选择两者模型的任意 config
© 版权声明
模型版权归作者所有,仅供娱乐,请于下载后24小时内删除。侵权联系 mxgf.cc@foxmail.com
THE END




























暂无评论内容