
常见推理参数详解
自动 f0 预测
基本上是一个自动变调功能,可以将模型音高匹配到推理源音高,用于说话声音转换时可以打开,能够更好匹配音调。
f0 预测器
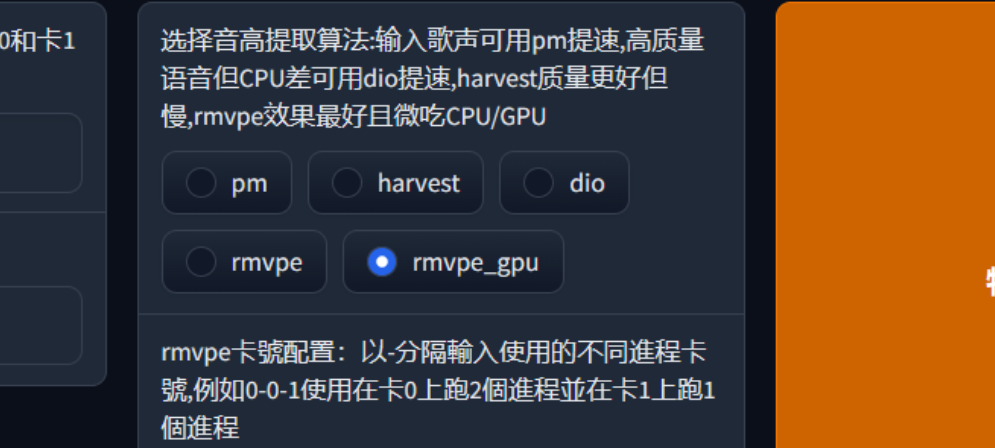
在推理时必须选择一个 f0 预测算法。以下是各个预测器算法在推理时的优缺点:
|
预测器 |
优点 |
缺点 |
|
pm |
速度快,占用低 |
容易出现哑音 |
|
crepe |
基本不会出现哑音 |
显存占用高,自带均值滤波,因此可能会出现跑调 |
|
dio |
– |
可能跑调 |
|
harvest |
低音部分有更好表现 |
其他音域就不如别的算法了 |
|
rmvpe |
六边形战士,目前最完美的预测器 |
几乎没有缺点(极端长低音可能会出错) |
|
fcpe |
SVC 开发组自研,目前最快的预测器,且有不输 crepe 的准确度 |
– |
聚类模型/特征检索混合比例
该参数控制的是使用聚类模型/特征检索模型时线性参与的占比。聚类模型和特征检索均可以有限提升音色相似度,但带来的代价是会降低咬字准确度(特征检索的咬字比聚类稍好一些)。该参数的范围为 0-1, 0为不启用,越靠近 1, 则音色越相似,咬字越模糊。
聚类模型和特征检索共用这一参数,当加载模型时使用了何种模型,则该参数控制何种模型的混合比例。
注意,当未加载聚类模型或特征检索模型时,请保持改参数为 0,否则会报错。
切片阈值
推理时,切片工具会将上传的音频根据静音段切分为数个小段,分别推理后合并为完整音频。这样做的好处是小段音频推理显存占用低,因而可以将长音频切分推理以免爆显存。切片阈值参数控制的是最小满刻度分贝值,低于这个值将被切片工具视为静音并去除。因此,当上传的音频比较嘈杂时,可以将该参数设置得高一些(如 -30),反之,可以将该值设置得小一些(如 -50)避免切除呼吸声和细小人声。
开发组近期的一项测试表明,较小的切片阈值(如-50)会改善输出的咬字,至于原理暂不清楚。
自动音频切片
上面提到,推理时,切片工具会将上传的音频根据静音段切分为数个小段,分别推理后合并为完整音频。但有时当人声过于连续,长时间不存在静音段时,切片工具也会相应切出来过长的音频,容易导致爆显存。自动音频切片功能则是设定了一个最长音频切片时长,初次切片后,如果存在长于该时长的音频切片,将会被按照该时长二次强制切分,避免了爆显存的问题。
强制切片可能会导致音频从一个字的中间切开,分别推理再合并时可能会存在人声不连贯。你需要在高级设置中设置强制切片的交叉淡入长度来避免这一问题。
使用 Whisper-PPG 编码器的模型时,会自动设置一个 25 秒的强制切片,否则会无法正常推理。
文本转语音
文本转语音使用微软的 edge_TTS 服务生成一段原始语音,再通过 So-VITS 将这段语音的声线转换为目标声线。
So-VITS 只能实现歌声转换 (SVC) 功能,没有任何原生的文本转语音 (TTS) 功能!
目前文本转语音共支持 55 种语言,涵盖了大部分常见语言。程序会根据文本框内输入的文本自动识别语言并转换。
自动识别只能识别到语种,而某些语种可能涵盖不同的口音,说话人,如果使用了自动识别,程序会从符合该语种和指定性别的说话人种随机挑选一个来转换。如果你的目标语种说话人口音比较多(例如英语),建议手动指定一个口音的说话人。如果手动指定了说话人,则先前手动选择的性别会被抑制。




























暂无评论内容